Written by Maria A. Serrano (Barcelona Supercomputing Center).
Current trends towards the use of big data analytics in the context of smart cities suggest the need of novel software development ecosystems upon which advanced mobility functionalities can be developed. These new ecosystems must have the capability of collecting and processing vast amount of geographically-distributed data, and transform it into valuable knowledge for public sector, private companies and citizens. ELASTIC is facing this need by developing a software architecture framework capable of efficiently exploiting the computing capabilities of the compute continuum, while guaranteeing the real-time, energy, communication quality and security non-function properties of the system.
COMPSs [1] is at the heart of the software architecture: it is the component responsible for efficiently distributing, across the compute continuum, the different data analytics methods, each described as a COMPSs workflow. Moreover, COMPSs includes the deployment capabilities to interact with hybrid resources in a transparent way for the programmer. A novel elasticity concept is considered to dynamically adapt the workflow distribution whilst fulfilling non-functional properties. Next, the programming model and the deployment capabilities of COMPSs are described.
COMPSs programming framework
COMPSs provides a simple, yet powerful, tasking programming model, in which the programmer identifies the data analytics functions, named COMPSs tasks, on top of general purpose programming languages, such as Python, Java or C/C++. The COMPSs runtime is then in charge of selecting the most suitable computing resources in which tasks can execute, while maintaining the hybrid fog computing platform transparent to the programmer. A COMPSs data analytics workflow can be represented as a Direct Acyclic Graph (DAG) to express its parallelism. Each node corresponds to a COMPSs task and edges represent data dependencies between them. As an example, Figure 1 represents the DAG of a COMPSs data analytics workflow composed of five tasks (1,… 5) and four data dependencies between them (A, B, C, D). For instance, due to data dependency B, Task 4 must execute after Task 2 finishes its execution.
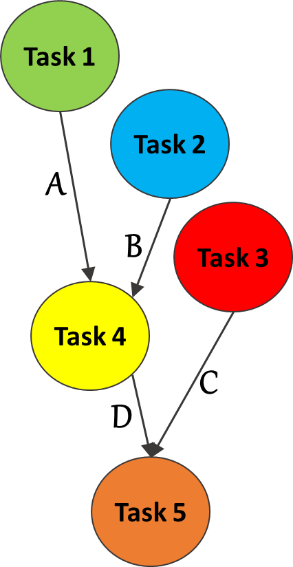
Figure 1. DAG representation of a COMPSs data analytics workflow.
COMPSs deployment capabilities
One of the main features of COMPSs is that the model abstracts the application from the underlying distributed infrastructure, hence COMPSs programs do not include any detail that could tie them to a particular platform boosting portability among diverse infrastructures and enabling execution in fog environments. It is the COMPSs runtime the one that features the capabilities to setup the execution environment.
The COMPSs runtime is organised as a master-worker structure. The Master executes in the resource where the application is launched, and it is responsible for steering the distribution of the application, as well as for implementing most of the features for initialising the execution environment, processing tasks, or data management. The Worker(s) are in charge of responding to task execution requests coming from the Master. There are three different scenarios currently supported for the deployment of COMPSs workers:
• Native Linux: data analytics tasks running directly on top of the OS.
• Docker containerized: data analytics tasks are encapsulated in Docker containers, running in a Docker platform [2].
• Cloud: data analytics tasks are encapsulated in Docker containers, running in a Docker Swarm [2] or Kubernetes [3] cloud platform. In the ELASTIC project this deployment is done through Nuvla [4].
As an example, Figure 2 shows the master-worker execution environment for the workflow in Figure 1. It is composed a COMPSs master, running in Node 1, where the workflow starts, and four extra COMPSs workers running in:
• Node 2, one COMPSs worker deployed as a Docker container,
• Node 3, one COMPSs worker deployed as a native Linux execution, and
• Cloud, two COMPSs workers deployed through the Nuvla API.
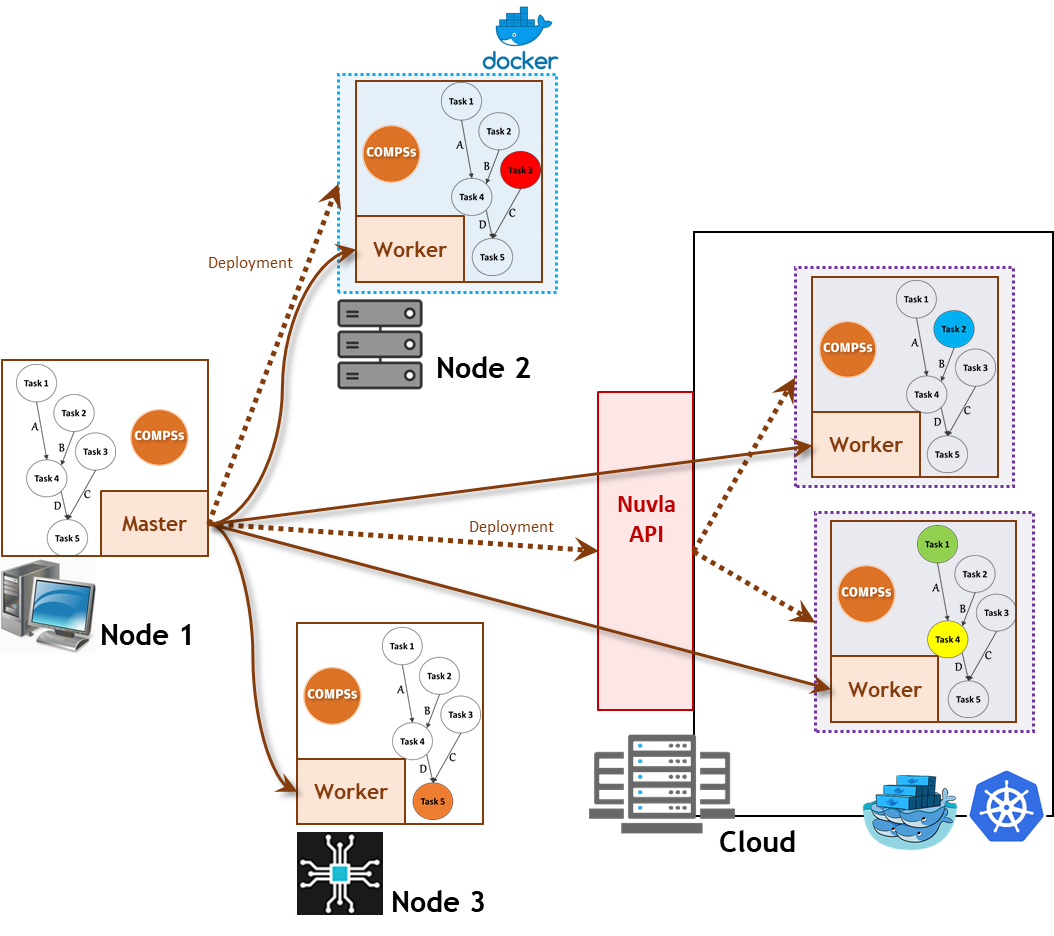
Figure 2. COMPSs master-worker execution environment.
In this example, tasks 1 and 4 are executed in a container in the Cloud; task 2 is executed in a different container, also in the Cloud; and tasks 3 and 5 are executed in Nodes 2, and 3, respectively.
This kind of execution scenarios, managed by COMPSs, ensure the coordination and interoperability of different edge/cloud resources, promoting a novel elascity concept among, not only cloud computing resources, but also edge devices.
References
[1] COMP Superscalar (COMPSs) http://compss.bsc.es/
[2] Docker and Docker Swarm https://www.docker.com/
[3] Kubernetes (K8s) https://kubernetes.io/
[4] Nuvla https://nuvla.io/